Playing Atari Pong with Reinforcement Learning
Background
In 2013 the relatively new AI startup DeepMind released their paper Playing Atari with Deep Reinforcement Learning detailing an artificial neural network that was able to play, not 1, but 7 Atari games with human and even super-human level proficiency. What made this paper so astounding was the fact that it was a single, general purpose neural network (a general artificial intelligence if you will) that could be trained to play all these games rather than 7 separate ones.
If this wasn’t enough, in 2015 they blew the machine learning community, and everyone else considering the news coverage, away with their paper Human-level control through deep reinforcement learning in which they construct what they call a Deep Q Network (DQN) to play 42 different Atari games, all of varying complexity, with performance that exceeded a professional human player.1
Q-Learning
The researchers at Google’s DeepMind achieved this stunning success with a type of machine learning called reinforcement learning and more specifically Q-learning. In essence, the goal of Q-learning is to approximate some ideal function $Q(s,a)$ that outputs a reward (how good we are doing at the task), where $s$ is a possible state of the environment/game/etc. and $a$ is a possible action to take in that state. If we had such a function, or even a good approximation, we could simply plug in our current state and choose whatever action will maximize $Q$ which would then maximize how well we perform the task. To approximate this function, the researchers used a convolutional neural network (CNN) and trained it using Q-learning, thus creating a Deep Q Network. You can read more about Q-learning and DQNs here.
By implementing Q-learning in a convolutional neural network (CNN) they create a DQN capable of predicting what actions to take based on the current state of the game.
Policy Gradients
That said, Q-learning isn’t the only way to achieve these results. Another popular type of reinforcement learning is what known as policy gradients. This method is more direct and conceptually simpler than Q-learning. Essentially, you input the current state, action taken, and reward given at every step and optimize the network accordingly.
And make no mistake, while simpler, policy networks can be just as good as DQNs. In fact, when tuned correctly, they perform even better than DQNs. Don’t believe me? Just ask the authors of the original paper themselves: Asynchronous Methods for Deep Reinforcement Learning.
My Attempt
Encouraged by the aforementioned research, I thought I would attempt to create an ANN capable of playing pong using reinforcement learning. To do this I used OpenAI’s Gym package to model Pong, and Google’s TensorFlow library to construct the network.
The code for this network, dubbed PongNet, is in my NeuralNetwork repository on GitHub.
Results
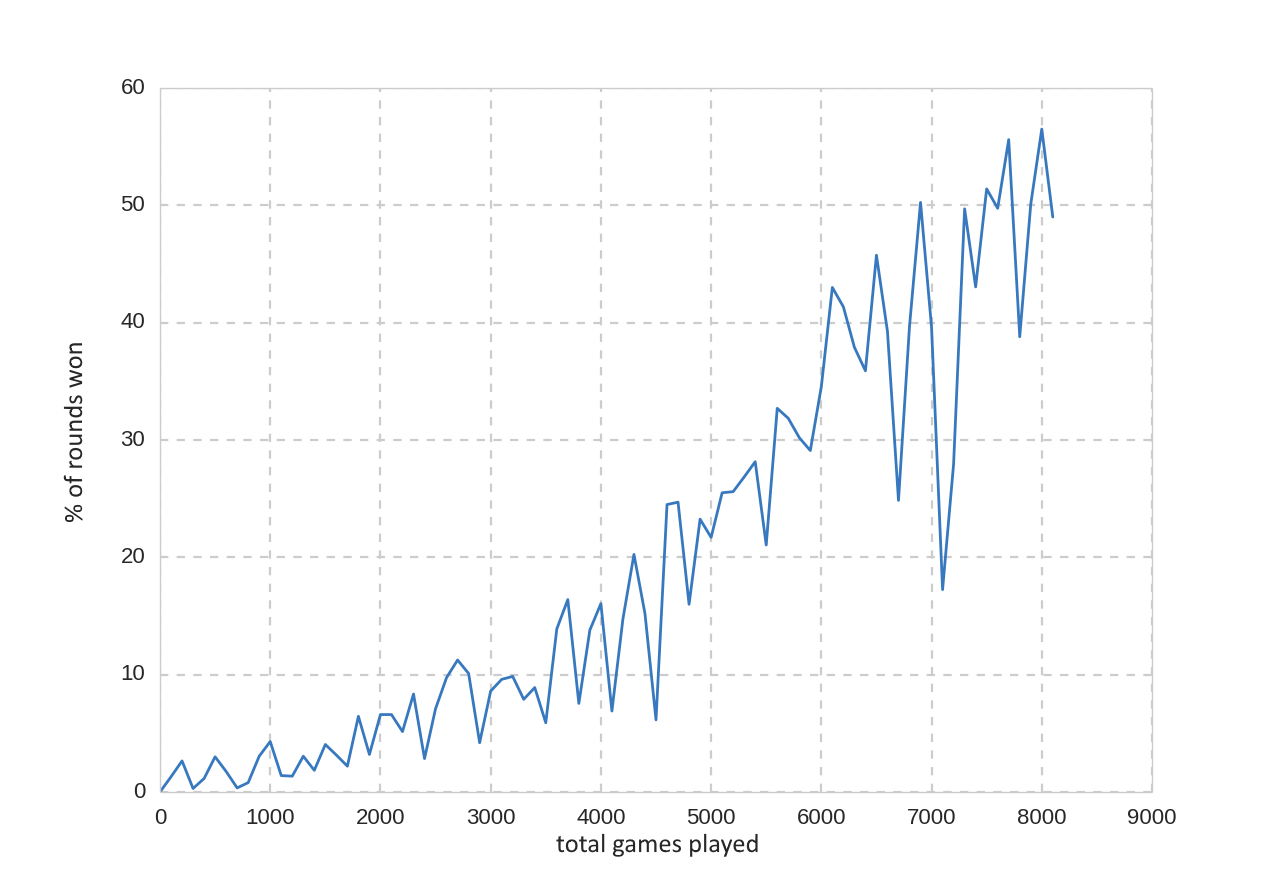
Learning starts to appear after 1500 games (a game goes on until one player reaches 20 points) and it reaches a 50% win-rate at around 8000 games. More testing needs to be done to see the maximum accuracy of this particular network.
Below is the network (on a good day) playing against the same bot it trained with for 10,000 games.
